The honeymoon phase of generative AI in the financial sector has met its regulatory reckoning. A recent warning from EU regulators has sent a clear signal to banks and fintechs alike: the current “black box” approach to large language models is incompatible with modern financial stability. For a sector built on trust and deterministic logic, the probabilistic — and often leaky — nature of AI creates a new, volatile cybersecurity frontier.
How AI Expands the Cybersecurity Attack Surface
Traditional security systems follow deterministic rules. AI models adapt, learn, and sometimes behave unpredictably — and that unpredictability is the vulnerability. Machine learning models depend on vast datasets; if those datasets are compromised, the model itself becomes an attack vector.
The most dangerous technique here is the model inversion attack. If a quantitative analyst uses a cloud-based AI to debug a proprietary trading algorithm, that algorithm’s logic can be “memorized” by the model. A competitor using the same platform could then extract that logic through carefully crafted queries — leading to competitive loss and potential market manipulation. Attack surfaces also expand through APIs and third-party integrations, giving adversaries multiple points of entry.
Why regulators are paying attention:
- AI models can unintentionally memorize sensitive customer data during training
- Outputs may reveal confidential information through prompt manipulation
- Attack surfaces multiply through APIs, plugins, and third-party integrations
- The probabilistic nature of AI makes security audits fundamentally harder than with rule-based systems
The Anatomy of LLM-Driven Data Leakage
The most silent threat regulators are tracking is the “unintended training” loop. In a standard cloud-based AI setup, every query and financial dataset sent to a provider risks being integrated into the model’s future weights. This is data leakage at its most invisible — and its most consequential.
Financial leads must understand the inference-to-training pipeline. To mitigate this, firms should move toward stateless inference environments where data is purged the moment a response is generated. In practice, this means choosing AI infrastructure where contractual protections — and verifiable technical controls — ensure no training on customer inputs.
In financial environments, even small leaks are catastrophic. Exposed trading strategies, customer identities, or proprietary algorithms can cause irreversible competitive and regulatory damage before a breach is even detected.
Legal Data Risk in AI: A Compliance Collision
The EU regulatory warning specifically highlights the collision between privacy law and AI architecture. Under GDPR, customers hold the “Right to be Forgotten.” But if a customer’s financial history was inadvertently used to fine-tune a model, that model is technically in violation the moment the deletion request arrives — because there is no reliable way to remove a specific individual’s influence from a trained neural network.
Three compliance challenges dominate the regulatory conversation:
- Lack of transparency in AI decision-making, making audit trails difficult to construct
- Difficulty attributing accountability when AI-generated outputs cause harm or violate rules
- Cross-border data flow risks when cloud AI providers process EU-regulated financial data across jurisdictions
The solution is to treat compliance as an architectural constant rather than a post-process. Implementing differential privacy at the data ingress layer — adding mathematical noise to datasets before they interact with an AI — allows models to learn general financial patterns without memorizing specific individual records. It is technically possible to gain insight without creating irreversible personal data exposure.
This is a meaningful distinction: it means a bank can build a smarter credit model without creating a legal liability every time a customer submits a data deletion request.
The Fragility of Public AI Supply Chains
A bank’s cybersecurity posture is only as strong as its least secure AI vendor. Recent vulnerabilities in shared cloud AI platforms have demonstrated that API keys, prompt histories, and financial intellectual property are all exposed when a provider is compromised. This is a supply chain risk that traditional security frameworks were not designed to handle.
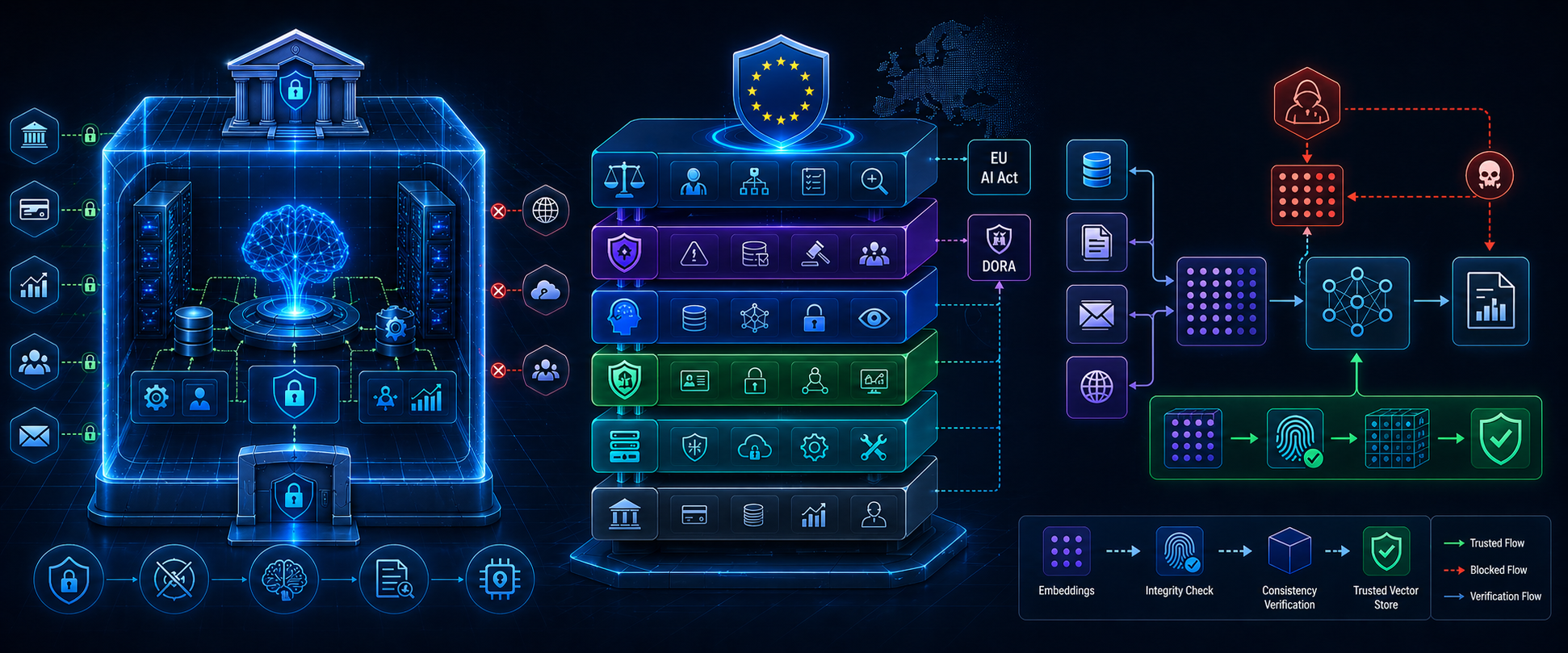
The architectural answer is sovereignty: hosting AI models locally within a hardened internal perimeter rather than depending on external cloud infrastructure. This decouples a bank’s security posture from the fluctuating vulnerabilities of the public AI market. Questa AI is one platform built specifically for this requirement — providing local-first, sovereign AI infrastructure that keeps financial intelligence and customer data within the institution’s own controlled environment, rather than routing it through shared external systems.
Data Sovereignty is not merely a compliance checkbox. In a volatile digital economy, it is a competitive differentiator: institutions that do not depend on third-party AI providers cannot be compromised through them.
Adversarial AI and the Vector Database Risk
As financial institutions adopt Retrieval-Augmented Generation (RAG) — systems that allow AI to search internal documents before responding — a new attack surface emerges: vector poisoning. If an attacker gains write access to an internal document repository and injects malicious embeddings, they can effectively manipulate what the AI “knows” and how it responds to queries.
The mitigation is vector integrity verification. Just as code is cryptographically signed before deployment, embeddings in a financial vector database must be signed. When the AI retrieves information to answer a query, it should first verify the cryptographic signature. If the embedding has been altered, the AI refuses to process it. This is the only technically sound way to secure data in an environment where internal documentation is continuously updated.
Security teams that have implemented Agentic RAG without this layer are running an unsigned, unverified knowledge base inside their AI — and may not know it has been tampered with.
What Securing Data with AI Actually Looks Like
Securing AI in financial systems is not about adding another security layer on top of existing architecture. It requires rethinking how data flows through systems end to end. Four practical approaches that work:
Data Minimization
Train models only on the data strictly necessary for the task. Every additional data point is an additional liability. Less data reduces both the model’s attack surface and its legal risk exposure.
Model Isolation
Separate sensitive models from public-facing systems. A model that processes internal trading data should never share infrastructure with a customer-facing chatbot.
Output Filtering
Implement controls that scan AI-generated outputs before they are released to users. This catches unintentional memorization and compliance violations before they reach the customer or regulator.
Continuous Monitoring
AI systems evolve. Security must be dynamic and iterative, not a one-time deployment checklist. Model behavior should be audited on a schedule, not just at launch.